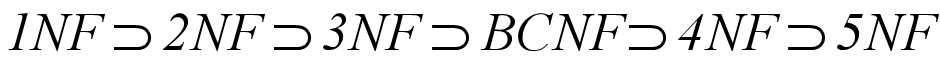template<classT>//声明一个模板,告诉编译器后面代码中紧跟的T是一个通用数据类型 voidSwap(T& a, T& b){ T temp = a; a = b; b = temp; } voidtest01(){ int a = 10; int b = 20; //利用模板实现交换 //1.自动类型推导 Swap(a,b); //2.显示指定类型 Swap<int>(a,b); cout << "a = " << a << endl; cout << "b = " << b << endl; return; }
template<classT>//声明一个模板,告诉编译器后面代码中紧跟的T是一个通用数据类型 voidSwap(T& a, T& b){ T temp = a; a = b; b = temp; } voidtest01(){ int a = 10; int b = 20; char c ='c'; Swap(a,b);//正确,可以推导出一致的T //Swap(a,c);//错误,推导不出一致的T,T到底是int还是char return; } template<classT> voidfunc(){ cout<<"func"<<endl; } voidtest02(){ //func(); //错误,模板不能独立使用,必须确定出T的类型 func<int>(); //利用显示指定类型的方式,给T一个类型,才可以使用该模板 }
3 普通函数与模板函数的区别
普通函数与函数模板区别:
普通函数调用时可以发生自动类型转换(隐式类型转换)
函数模板调用时,如果利用自动类型推导,不会发生隐式类型转换
如果利用显示指定类型的方式,可以发生隐式类型转换
示例:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
intmyadd01(int a,int b){ return a + b; } template<classT> T myadd02(T a,T b){ return a + b; } voidtest01(){ int a = 10; int b = 20; char c = 'c'; //正确,将char类型的'c'隐式转换为int类型'c'对应的ASCII码99 cout<<myadd01(a,c)<<endl; //myadd02(a,c);//报错,使用自动类型推导时,不会发生隐式类型转换 myadd02<int>(a,c);//正确,如果显示指定类型,可以发生隐式类型转换 }
classPerson { public: Person(string name, int age) { this->m_Name = name; this->m_Age = age; } string m_Name; int m_Age; }; //普通函数模板 template<classT> boolmyCompare(T& a, T& b) { if (a == b) returntrue; elsereturnfalse; } //具体化,显示具体化的原型和定意思以template<>开头,并通过名称来指出类型 //具体化优先于常规模板 template<> boolmyCompare(Person &p1, Person &p2){ if ( p1.m_Name == p2.m_Name && p1.m_Age == p2.m_Age) returntrue; elsereturnfalse; } voidtest01(){ int a = 10; int b = 20; //内置数据类型可以直接使用通用的函数模板 bool ret = myCompare(a, b); if (ret) cout << "a == b " << endl; elsecout << "a != b " << endl; }
voidtest02(){ Person p1("Tom", 10); Person p2("Tom", 10); //自定义数据类型,不会调用普通的函数模板 //可以创建具体化的Person数据类型的模板,用于特殊处理这个类型 bool ret = myCompare(p1, p2); if (ret) cout << "p1 == p2 " << endl; elsecout << "p1 != p2 " << endl; }
SELECT [ALL|DISTINCT] <目标列表达式> [,<目标列表达式>] … FROM <表名或视图名>[, <表名或视图名> ] … [ WHERE <条件表达式> ] [ GROUP BY <列名1> [ HAVING <条件表达式> ] ] [ ORDER BY <列名2> [ ASC|DESC ] ];
SELECT Sno,Sname FROM Student; SELECT * FROM Student; //SELECT子句的<目标列表达式>可以为:算术表达式、字符串、常量函数、列别名 SELECT Sname,2009-Sage FROM Student; SELECT Sname,LOWER(Sdept) FROM Student;//小写字母表示所有系名 SELECT Sname NAME,LOWER(Sdept) DEPARTMENT FROM Student;
(2) 选择表中的若干元组
消除取值重复的行,如果没有指定DISTINCT关键词,则缺省为ALL
指定DISTINCT关键词,去掉表中重复的行
1 2
SELECT Sno FROM SC;//等价于:SELECTALL Sno FROM SC; SELECTDISTINCT Sno FROM SC;
//查询计算机科学系全体学生的名单。 SELECT Sname FROM Student WHERE Sdept=‘CS’;
//查询年龄在20~23岁(包括20岁和23岁)之间的学生的姓名、系别和年龄 SELECT Sname,Sdept,Sage FROM Student WHERE Sage BETWEEN20AND23; //查询信息系(IS)、数学系(MA)和计算机科学系(CS)学生的姓名和性别。 SELECT Sname,Ssex FROM Student WHERE Sdept IN ( 'IS','MA','CS' ); //匹配串为固定字符串 //查询学号为200215121的学生的详细情况。 SELECT * FROM Student WHERE Sno LIKE'200215121'; //匹配串为含通配符的字符串 //查询所有姓刘学生的姓名、学号和性别。 SELECT Sname,Sno,Ssex FROM Student WHERE Sname LIKE ‘刘%’;
//查询以"DB_"开头,且倒数第3个字符为 i的课程的详细情况。 SELECT * FROM Course WHERE Cname LIKE'DB\_%i_ _' ESCAPE '\'; //查所有有成绩的学生学号和课程号。 SELECT Sno,Cno FROM SC WHERE Grade ISNOTNULL;
(3)ORDER BY子句
ORDER BY子句
可以按一个或多个属性列排序
升序:ASC; 降序:DESC;缺省值为升序
当排序列含空值时
ASC:排序列为空值的元组最后显示
DESC:排序列为空值的元组最先显示
1 2 3 4
//查询全体学生情况,查询结果按所在系的系号升序排列,同一系中的学生按年龄降序排列。 SELECT * FROM Student ORDERBY Sdept,Sage DESC;
(4) 聚集函数
计数
COUNT([ DISTINCT | ALL ] *)
COUNT([ DISTINCT | ALL ] <列名>)
计算总和
SUM([ DISTINCT | ALL ] <列名>)
计算平均值
AVG([ DISTINCT | ALL ] <列名>)
最大最小值
MAX([ DISTINCT | ALL ] <列名>)
MIN([ DISTINCT | ALL ] <列名>)
1 2 3
查询选修了课程的学生人数。 SELECTCOUNT(DISTINCT Sno) FROM SC;
(5)GROUP BY子句
细化聚集函数的作用对象
未对查询结果分组,聚集函数将作用于整个查询结果
对查询结果分组后,聚集函数将分别作用于每个组
作用对象是查询的中间结果表
按指定的一列或多列值分组,值相等的为一组
1 2 3 4 5
查询选修了3门以上课程的学生学号。 SELECT Sno FROM SC GROUPBY Sno HAVINGCOUNT(*) >3;
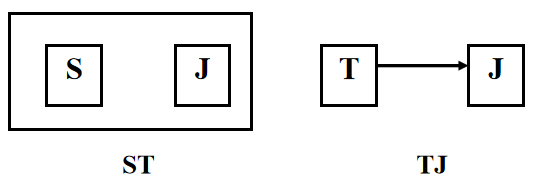
查询计算机科学系的学生及年龄不大于19岁的学生。 SELECT * FROM Student WHERE Sdept= 'CS' UNION SELECT * FROM Student WHERE Sage<=19; UNION:将多个查询结果合并起来时,系统自动去掉重复元组。 UNIONALL:将多个查询结果合并起来时,保留重复元组
连接查询:同时涉及多个表的查询
连接条件或连接谓词:用来连接两个表的条件
一般格式:
[<表名1>.]<列名1> <比较运算符> [<表名2>.]<列名2>
[<表名1>.]<列名1> BETWEEN [<表名2>.]<列名2> AND [<表名2>.]<列名3>
连接字段:连接谓词中的列名称
连接条件中的各连接字段类型必须是可比的,但名字不必是相同的
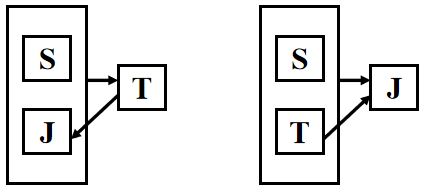
等值连接:连接运算符为 = 查询每个学生及其选修课程的情况
1 2 3
SELECT Student.*,SC.* FROM Student,SC WHERE Student.Sno = SC.Sno;
自然连接: 查询每个学生及其选修课程的情况
1 2 3
SELECT Student.Sno,Sname,Ssex,Sage,Sdept,Cno,Grade FROM Student,SC WHERE Student.Sno = SC.Sno;
查询与“刘晨”在同一个系学习的学生。 SELECT Sno,Sname,Sdept FROM Student WHERE Sdept IN (SELECT Sdept FROM Student WHERE Sname= ‘ 刘晨 ’); 用自身连接完成查询要求 SELECT S1.Sno,S1.Sname,S1.Sdept FROM Student S1,Student S2 WHERE S1.Sdept = S2.Sdept AND S2.Sname = '刘晨';
带有比较运算符的子查询
当能确切知道内层查询返回单值时,可用比较运算符(>,<,=,>=,<=,!=或< >)。
与ANY或ALL谓词配合使用
1 2 3 4 5 6 7 8 9 10 11 12
假设一个学生只可能在一个系学习,并且必须属于一个系, SELECT Sno,Sname,Sdept FROM Student WHERE Sdept = (SELECT Sdept FROM Student WHERE Sname= ‘刘晨’); 找出每个学生超过他选修课程平均成绩的课程号。 SELECT Sno, Cno FROM SC x WHERE Grade >=( SELECTAVG(Grade) FROM SC y WHERE y.Sno=x.Sno ) ;
带有ANY(SOME)或ALL谓词的子查询
1 2 3 4 5 6 7
查询其他系中比计算机科学某一学生年龄小的学生姓名和年龄 SELECT Sname,Sage FROM Student WHERE Sage < ANY (SELECT Sage FROM Student WHERE Sdept= ' CS ') AND Sdept <> ‘CS ' ;
/*在Student表的Sname(姓名)列上建立一个聚簇索引*/ CREATE CLUSTER INDEX Stusname ON Student(Sname); /* SC表按学号升序和课程号降序建唯一索引*/ CREATEUNIQUEINDEX SCno ON SC(Sno ASC,Cno DESC);
删除索引时,系统会从数据字典中删去有关该索引的描述。
4 数据更新
插入数据
修改数据
语句格式 UPDATE <表名>
SET <列名>=<表达式>[,<列名>=<表达式>]…
[WHERE <条件>];
功能 修改指定表中满足WHERE子句条件的元组的指定列值
删除数据
语句格式
DELETE
FROM <表名>
[WHERE <条件>];
1 2 3 4 5 6 7 8 9 10 11 12
/*插入一条选课记录( '200215128','1 ')。*/ INSERTINTO SC(Sno,Cno) VALUES (‘ 200215128 ’,‘1'); /*将计算机科学系全体学生的成绩置零。*/ UPDATE SC SET Grade=0 WHERE 'CS'= (SELETE Sdept FROM Student WHERE Student.Sno = SC.Sno); /*删除学号为200215128的学生记录。*/ DELETE FROM Student WHERE Sno= ‘200215128 ';
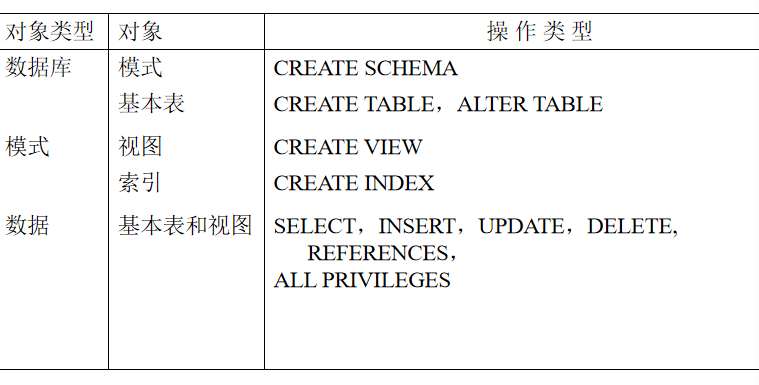
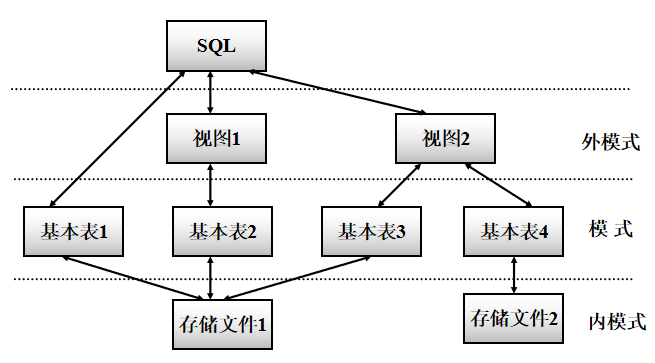
5 视图
视图的特点
虚表,是从一个或几个基本表(或视图)导出的表
只存放视图的定义,不存放视图对应的数据
基表中的数据发生变化,从视图中查询出的数据也随之改变
基于视图的操作
查询
删除
受限更新
定 义基于该视图的新视图。
定义视图
语句格式
CREATE VIEW <视图名> [(<列名> [,<列名>]…)]
AS <子查询>
[WITH CHECK OPTION];
/*建立信息系学生的视图,并要求进行修改和插入操作时仍需保证该视图只有信息系的学生。*/ CREATEVIEW IS_Student AS SELECT Sno,Sname,Sage FROM Student WHERE Sdept= 'IS' WITHCHECKOPTION; /* 带WITH CHECK OPTION选项时对IS_Student视图的更新操作: 修改操作:自动加上Sdept= 'IS'的条件 删除操作:自动加上Sdept= 'IS'的条件 插入操作:自动检查Sdept属性值是否为'IS' 如果不是,则拒绝该插入操作 如果没有提供Sdept属性值,则自动定义Sdept为'IS' */
基于多个基表的视图
1 2 3 4 5 6 7 8
/*建立信息系选修了1号课程的学生视图。*/ CREATEVIEW IS_S1(Sno,Sname,Grade) AS SELECT Student.Sno,Sname,Grade FROM Student,SC WHERE Sdept= 'IS'AND Student.Sno=SC.Sno AND SC.Cno= '1';
基于视图的视图
1 2 3 4 5 6
/* 建立信息系选修了1号课程且成绩在90分以上的学生的视图。*/ CREATEVIEW IS_S2 AS SELECT Sno,Sname,Grade FROM IS_S1 WHERE Grade>=90;
带表达式的视图
1 2 3 4 5
/*定义一个反映学生出生年份的视图。*/ CREATEVIEW BT_S(Sno,Sname,Sbirth) AS SELECT Sno,Sname,2007-Sage FROM Student;
分组视图
1 2 3 4 5 6
/*将学生的学号及他的平均成绩定义为一个视图,假设SC表中“成绩”列Grade为数字型*/ CREATEVIEW S_G(Sno,Gavg) AS SELECT Sno,AVG(Grade) FROM SC GROUPBY Sno;