第二章 关系数据库
1 关系数据结构及形式化定义
二维表:逻辑结构,从用户角度,关系模型中数据的逻辑结构是一张二维表
建立在集合代数的基础上
域:一组具有相同数据类型的值的集合
笛卡尔积:给定一组域D1,D2,…,Dn,这些域中可以有相同的。
D1×D2×…×Dn ={(d1,d2,…,dn)|di属于Di,i=1,2,…,n}
元组:笛卡尔积中每一个元素(d1,d2,…,dn)叫作一个n元组(n-tuple)或简称元组(Tuple)
(张三,计算机专业,男)等都是元组 ,通常用t表示
分量:笛卡尔积元素(d1,d2,…,dn)中的每一个值di叫作一个分量。张三,计算机专业,男等都是分量
基数:若Di(i=1,2,…,n)为有限集,其基数为mi(i=1,2,…,n),则D1×D2×…×Dn的基数M为:M = M1M2…..*Mn表示方法:笛卡尔积可表示为一个二维表,表中的每行对应一个元组,表中的每列对应一个域
示例:D1为教师集合(T)= {t1,t2}, D2为学生集合(S)= {s1,s2 ,s3},D3为课程集合(C)= {c1,c2}
则D1×D2×D3是个三元组集合,元组个数为2×3×2,是所有可能的(教师,学生,课程)元组集合子集
- 关系
D1×D2×…×Dn的子集叫作在域D1,D2,…,Dn上的关系,表示为R(D1,D2,…,Dn)
R:关系名
n:关系的目或度(Degree)- 元组
关系中的每个元素是关系中的元组,通常用t表示。 - 单元关系与二元关系
当n=1时,称该关系为单元关系(Unary relation)或一元关系
当n=2时,称该关系为二元关系(Binary relation)
- 元组
- 关系的表示
关系也是一个二维表,表的每行对应一个元组,表的每列对应一个域- 属性
关系中不同列可以对应相同的域,为了加以区分,必须对每列起一个名字,称为属性。n目关系必有n个属性
- 属性
候选码(Candidate key):若关系中的某一属性组的值能唯一地标识一个元组,则称该属性组为候选码。简单的情况:候选码只包含一个属性
全码(All-key):最极端的情况:关系模式的所有属性组是这个关系模式的候选码,称为全码
主码:若一个关系有多个候选码,则选定其中一个为主码(Primary key)
主属性:候选码的诸属性称为主属性(Prime attribute)
不包含在任何侯选码中的属性称为非主属性( Non-Prime attribute)或非码属性(Non-key attribute)三类关系
基本关系(基本表或基表):实际存在的表,是实际存储数据的逻辑表示
查询表:查询结果对应的表
视图表:由基本表或其他视图表导出的表,是虚表,不对应实际存储的数据关系模式:是型,是对关系的描述,是静态的、稳定的
- 是元素集合的结构
- 元组语义以及完整性约束条件
- 属性间的数据依赖关系集合
通常简记为R (U) 或 R (A1,A2,…,An) R: 关系名 A1,A2,…,An : 属性名
关系数据库
在一个给定的应用领域中,所有关系的集合构成一个关系数据库
- 型:关系数据库模式,包括若干域的定义;在这些域上定义的若干关系模式。
- 值:关系模式在某一时刻对应的关系的集合,简称为关系数据库
2 关系操作
- 常用的关系操作
- 查询:选择、投影、连接、除、并、交、差
- 数据更新:插入、删除、修改,查询的表达能力是其中最主要的部分
- 选择、投影、并、差、笛卡尔积是5种基本操作
- 操作特点:
- 集合操作方式:操作的对象和结果都是集合,一次一集合的方式
- 高度非过程化:只要指出“做什么”,不需要描述“怎么做”
3 关系代数
- 关系数据库语言分类
- 关系代数语言:用对关系的运算来表达查询要求。代表:ISBL
- 关系演算语言:用谓词来表达查询要求
元组关系演算语言:谓词变元的基本对象是元组变量。代表:APLHA, QUEL
域关系演算语言:谓词变元的基本对象是域变量。代表:QBE - 关系代数和关系演算是相互等价的
- 具有关系代数和关系演算双重特点的语言。代表:SQL(Structured Query Language)
- 定义:关系数据库的一种抽象的查询语言,用对关系的运算来表达查询。
- 要素:运算对象(关系)、关系运算符
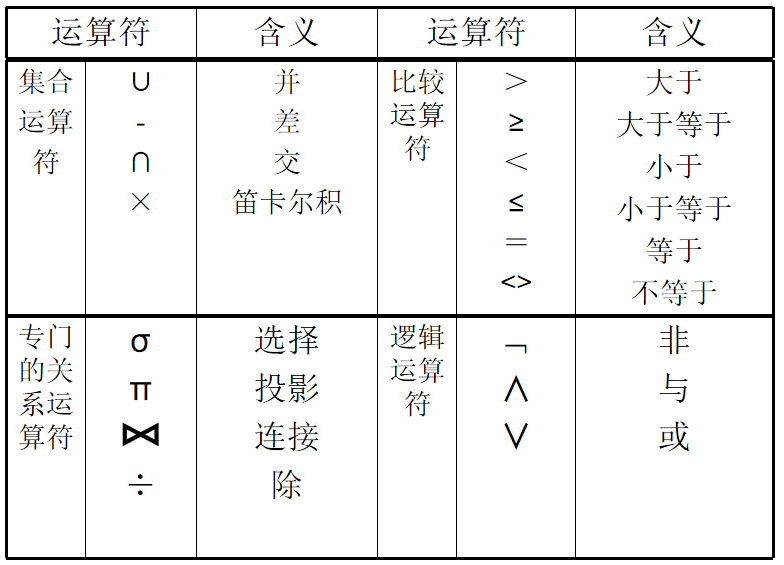
- 关系代数运算符
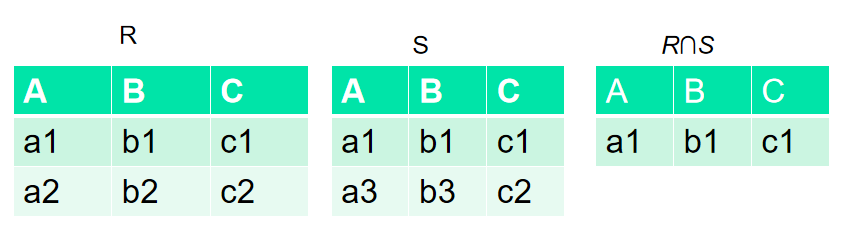
交
R和S:具有相同的目n;相应的属性取自同一个域
R∩S:仍为n目关系,由既属于R又属于S的元组组成
R∩S = { t|t 属于 R ∧ t 属于S }
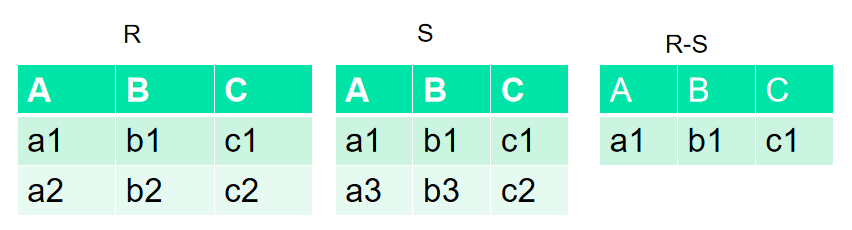
差
R和S:具有相同的目n,相应的属性取自同一个域
R - S :仍为n目关系,由属于R而不属于S的所有元组组成
R -S = { t|t属于R ∧ t属于S }
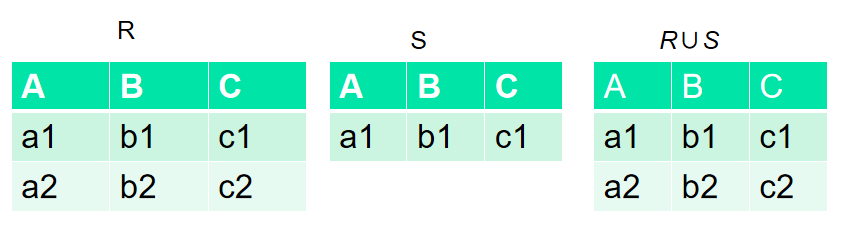
并
R和S:具有相同的目n(即两个关系都有n个属性),相应的属性取自同一个域
R∪S :仍为n目关系,由属于R或属于S的元组组成 R∪S = { t|t 属于 R ∨ t 属于S }
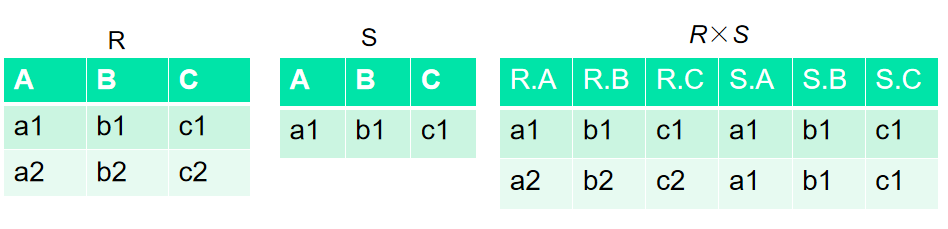
笛卡尔积
- 严格地讲应该是广义的笛卡尔积(Extended Cartesian Product)
R: n目关系,k1个元组
S: m目关系,k2个元组 - R×S
列:(n+m)列元组的集合,元组的前n列是关系R的一个元组,后m列是关系S的一个元组
行:k1×k2个元组
- 严格地讲应该是广义的笛卡尔积(Extended Cartesian Product)
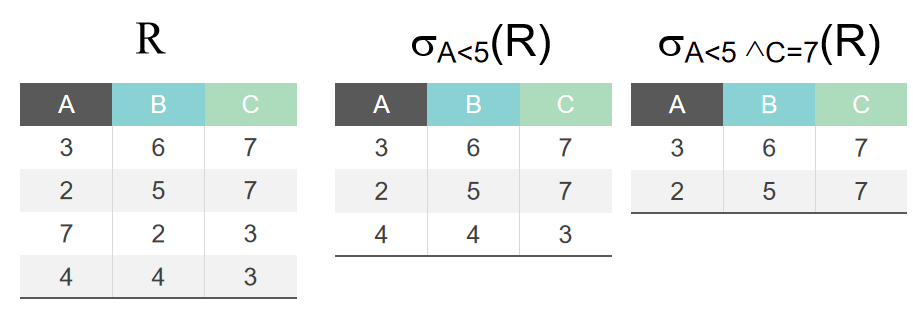
选择
在关系R中选择满足给定条件的元组 F(R)={t | t 属于 R ^F(t) = ‘真’}
F是选择的条件, F(t)要么为真,要么为假。F的形式:由逻辑运算符连接关系表达式而成
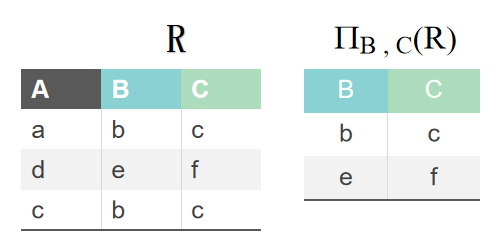
投影
从关系R中取若干列组成新的关系(从列的角度),投影的结果中要去掉相同的行
连接
连接操作是从两个关系的广义笛卡尔积中选择属性间满足一定条件的元组。通常写为:


等值连接和自然连接
等值连接:从关系R与S的广义笛卡尔积中选取A、B属性值相等的那些元组
自然连接:若R和S具有相同的属性组(来自相同的域,表示相同的含义),且连接的运算符θ为“=”,在连接的结果中去掉重复的属性组

外连接
如果把舍弃的元组也保存在结果关系中,而在其他属性上填空值(Null),这种连接就叫做外连接。左外连接
如果只把左边关系R中要舍弃的元组保留就叫做左外连接。右外连接
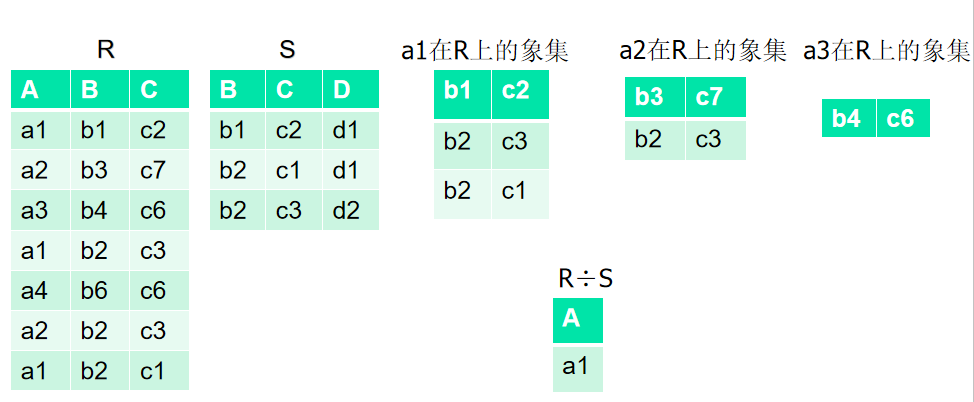
如果只把右边关系S中要舍弃的元组保留就叫做右外连接。象集
关系R(X , Z),X、 Z是属性组,x是X上的取值,定义x在R中的象集为从R中选出在X上取值为x的元组,去掉X上的分量,只留Z上的分量 Zx = { t[Z] | t属于R 且 t[X]= x }

除
- 给定关系R(X,Y)和S(Y,Z),其中X,Y,Z为属性组。R中的Y与S中的Y可以有不同的属性名,但必须出自相同的值域。
- R与S的除运算得到一个新的关系P(X),P是R中满足下列条件的元组在X属性列上的投影:元组在X上分量值x的象集Yx包含S在Y上投影的集合。
4 关系的完整性
- 实体完整性和参照完整性:关系模型必须满足的完整性约束条件,称为关系的两个不变性,应该由关系系统自动支持。
- 用户定义的完整性: 应用领域需要遵循的约束条件,体现了具体领域中的语义约束
- 实体完整性:若属性A是基本关系R的主属性,则属性A不能取空值
- 外码
- 设F是基本关系R的一个或一组属性,但不是关系R的码。如果F与基本关系S的主码Ks相对应,则称F是基本关系R的外码
- 基本关系R称为参照关系(Referencing Relation)
- 基本关系S称为被参照关系(Referenced Relation)或目标关系(Target Relation)
- 例:学生关系的“专业号”与专业关系的主码“专业号”相对应
“专业号”属性是学生关系的外码
专业关系是被参照关系,学生关系为参照关系 - 关系R和S不一定是不同的关系
- 目标关系S的主码Ks 和参照关系的外码F必须定义在同一个(或一组)域上
- 外码并不一定要与相应的主码同名,当外码与相应的主码属于不同关系时,往往取相同的名字,以便于识别
- 参照完整性
- 若属性(或属性组)F是基本关系R的外码,它与基本关系S的主码Ks相对应(基本关系R和S不一定是不同的关系),则对于R中每个元组在F上的值必须为:
- 或者取空值(F的每个属性值均为空值)
- 或者等于S中某个元组的主码值
- 若属性(或属性组)F是基本关系R的外码,它与基本关系S的主码Ks相对应(基本关系R和S不一定是不同的关系),则对于R中每个元组在F上的值必须为: